Performing Document Analysis Leveraging LLMs #
Key Challenge - The larger the document, the higher the probability of hallucinations #
This phenomenon, often referred to as “context rot” or “attention dilution,” is a significant challenge in working with Large Language Models (LLMs) on extensive texts. While LLMs are continually evolving with ever-larger context windows (the amount of text they can process at once), simply increasing the window doesn’t eliminate the problem. As the input document grows, the model’s ability to maintain coherent and accurate information across the entire span can degrade. Important details might get lost amidst a sea of less relevant text, or the model might struggle to accurately recall specific facts from the beginning or end of the document if the crucial information is buried in the middle.
This increased “noise” in the longer context can lead the LLM to generate plausible but incorrect or fabricated information – a hallucination – as it tries to fill in gaps or connect disparate pieces of information that it can no longer reliably track. This is why techniques like Retrieval-Augmented Generation (RAG) are becoming so critical, as they allow LLMs to focus on smaller, highly relevant chunks of information retrieved from a large document, rather than processing the entire document in one go.
AIKMS as a gateway to LLM #
To extract meaningful insights in larger documents more easily, I’ve developed a small, focused AI assistant within AIKMS to streamline this process directly within my Logseq environment. This custom application acts as a bridge, allowing me to query and analyze specific sections of any document I’m working on. It’s a pragmatic solution that provides an additional option for structured information extraction:
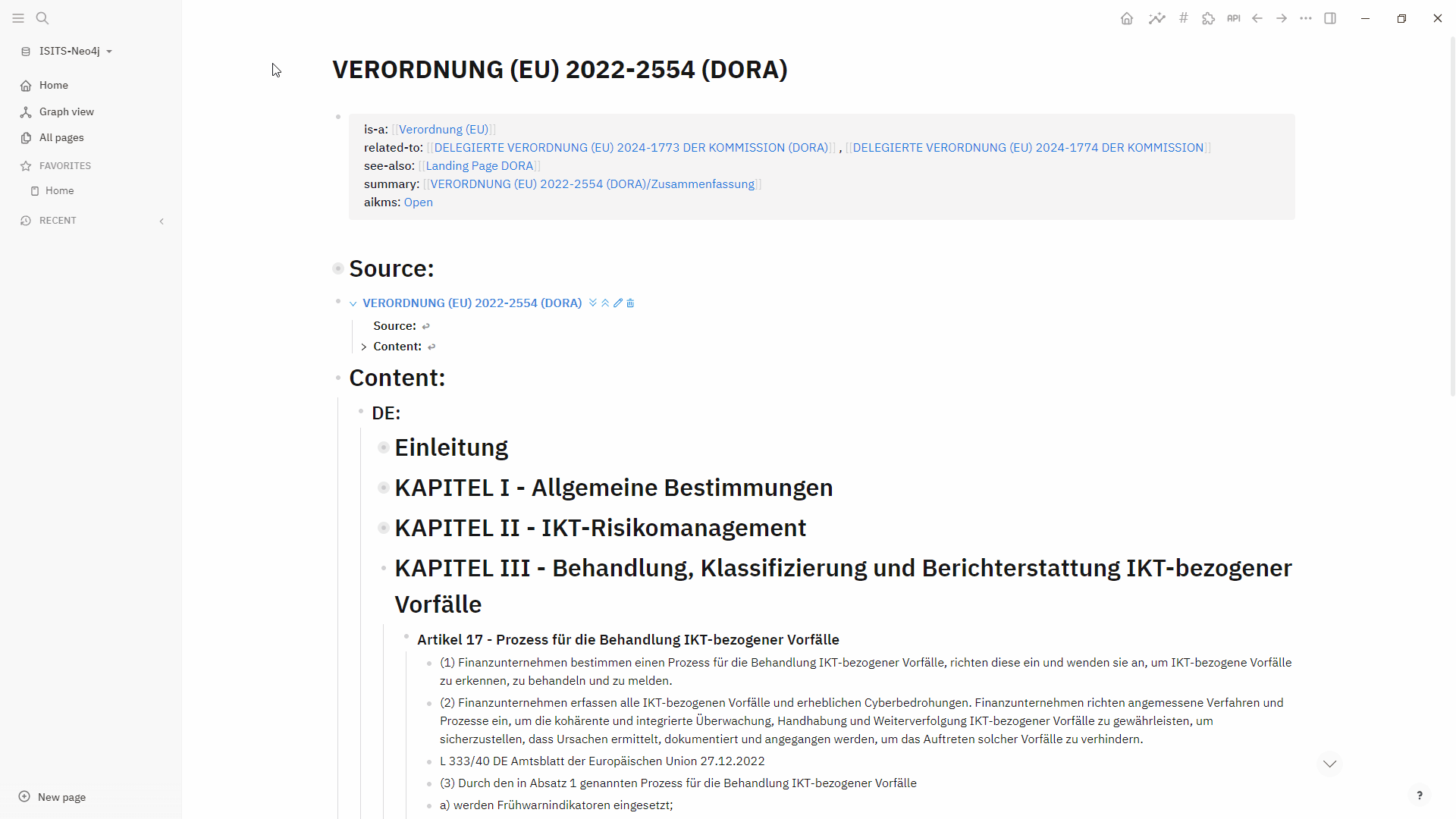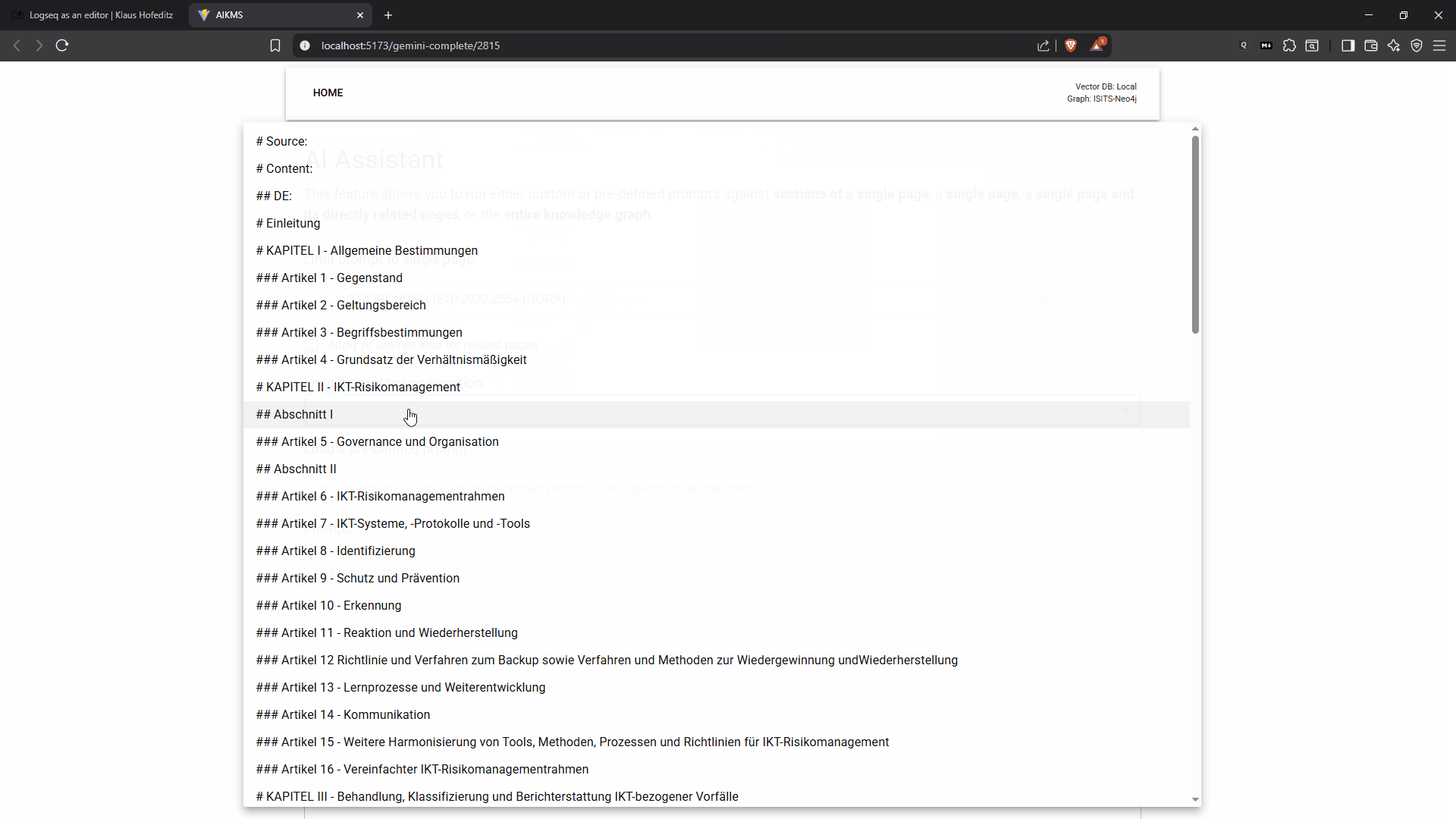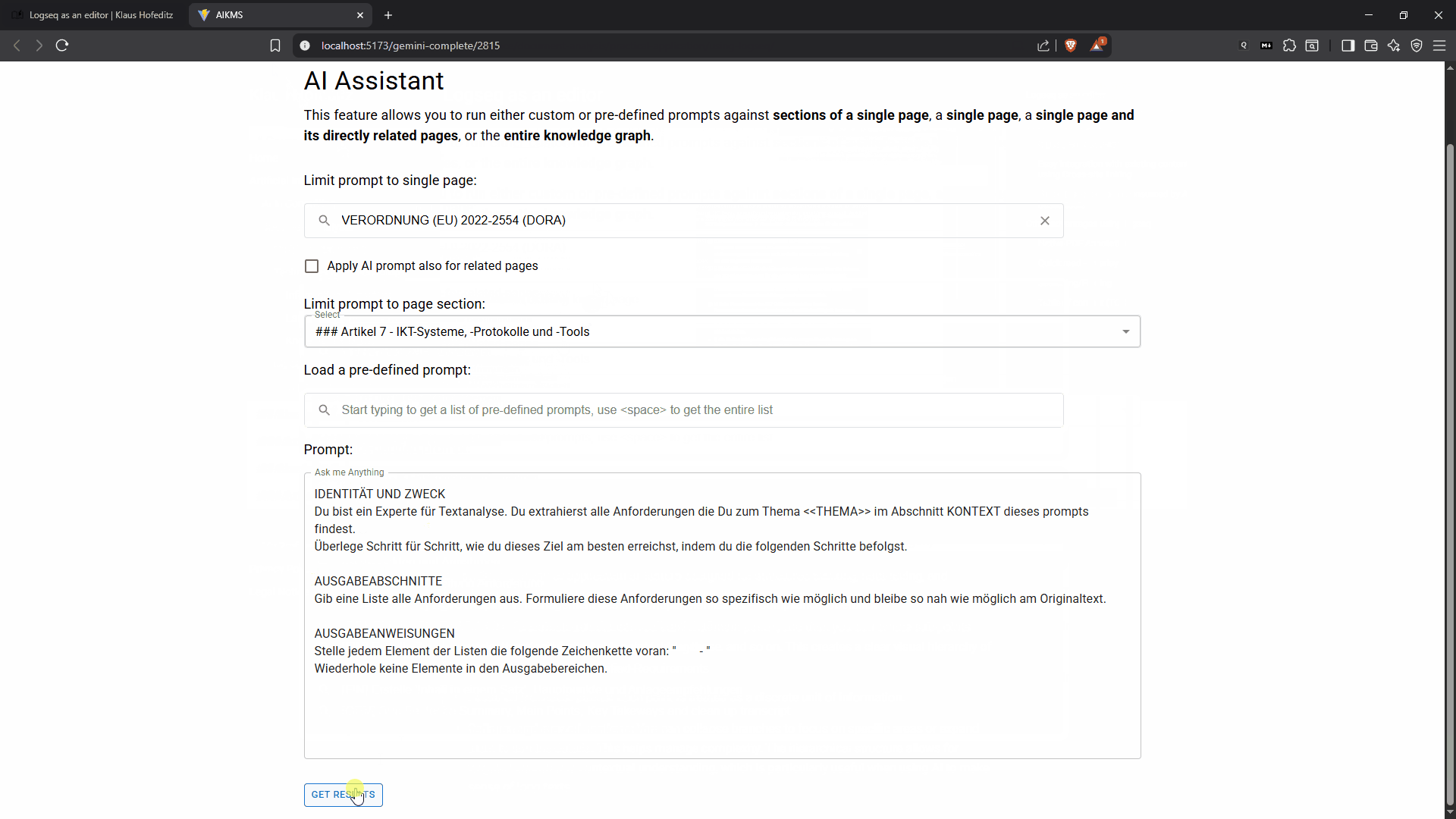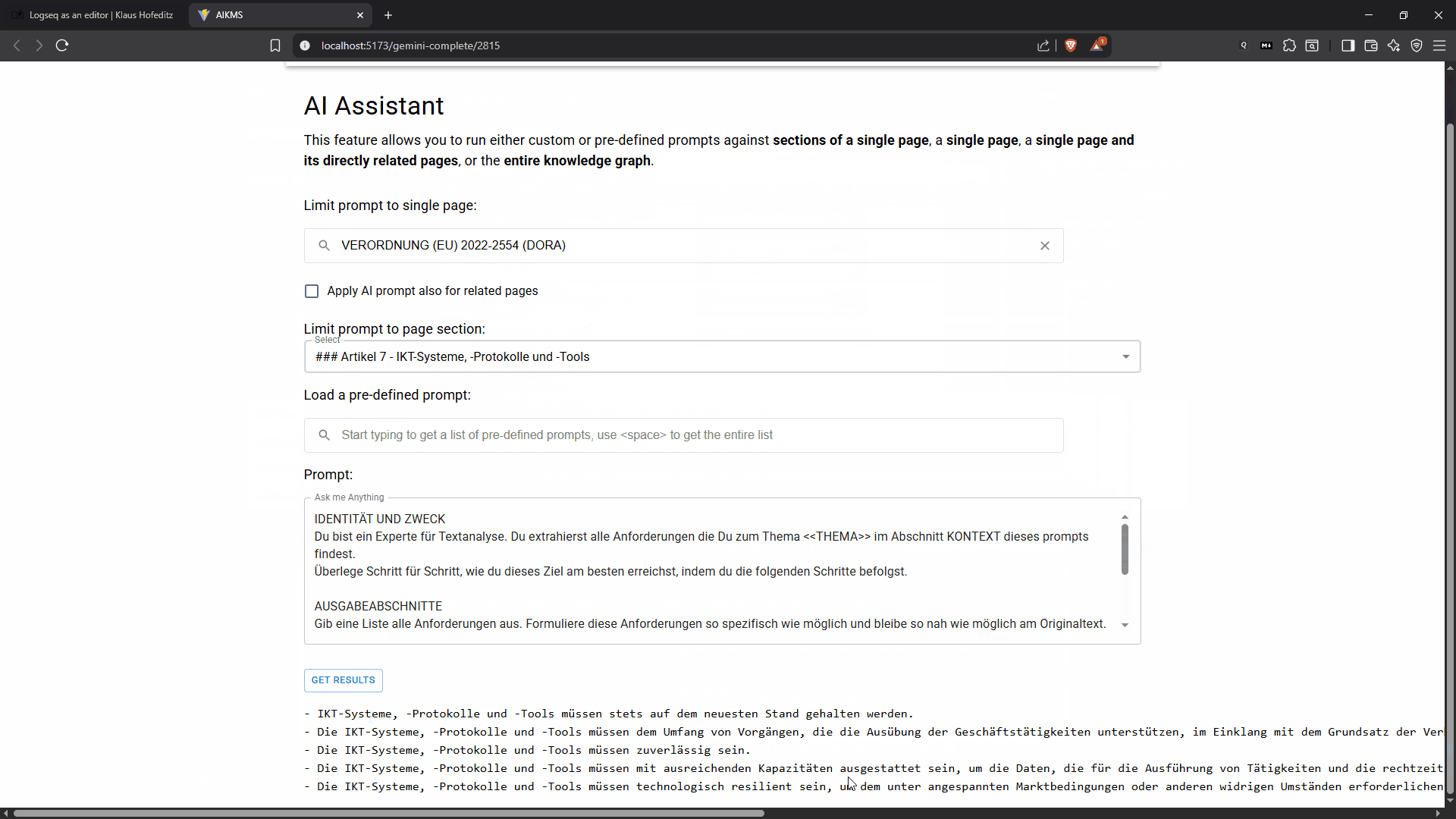
Running a pre-defined prompt against a section of a document (click to increase size)
To reduce the risk of halluzinations I can select any block or series of blocks from a Logseq document—perhaps a single article from a regulation or a key paragraph from a research paper—to serve as the AI’s context. From there, I have the flexibility to either choose from a set of predefined prompts for common tasks like summarizing, identifying key entities, or extracting control requirements, or I can formulate a new, specific prompt on the fly. This dual approach ensures that whether I need a quick overview or a deeply nuanced analysis, the tool is ready to assist.
Once I submit the query, the assistant securely connects to a public Large Language Model and returns the result. This integration allows me to leverage the power of advanced AI while meticulously controlling my source material. By feeding the LLM only the precise context it needs, I significantly mitigate the risk of hallucinations and ensure that the output is directly relevant to my source document. The returned result can then be further refined or seamlessly integrated into my existing notes, creating a dynamic and verifiable foundation for my analysis.