Information Extraction #
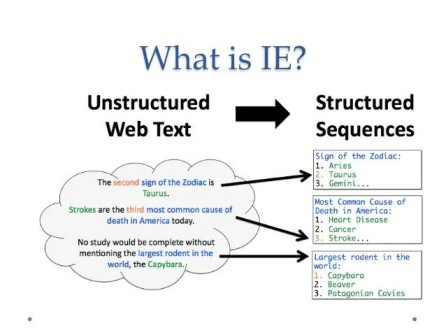
Information Extraction (IE) serves as a profoundly useful method for gaining a better understanding of large and complex documents by transforming unstructured text into structured, actionable data.
Source: Rubén Izquierdo Beviá
About Information Extraction #
In the journey from raw information to actionable insight, Information Extraction is a critical step. It is the process of automatically identifying and pulling structured data—such as entities, relationships, key terms, and other specific facts—from unstructured text. This makes it a core component of Document Analysis. Information Extraction provides the precise, machine-readable data that makes that understanding scalable and efficient. It is the engine that transforms passive documents into an active source of knowledge.
From Text to Data: How It Works #
By leveraging AI and NLP techniques, Information Extraction systematically identifies and extracts predefined types of information. For instance, in a lengthy legal contract, IE can automatically pinpoint all parties involved, critical dates, financial amounts, clauses pertaining to specific liabilities, and effective dates, presenting them in an easily digestible table or database.
This transformation into structured data allows users to query the document like a database, rather than sifting through prose. Instead of reading every paragraph, one can ask “Who are all the parties involved?” or “What are all the termination clauses?” and receive immediate, precise answers. This dramatically reduces the time spent on data discovery and eliminates the risk of missing vital information due to human fatigue or oversight.
Enabling Deeper Analysis and Visualization #
Furthermore, the structured output from information extraction enables downstream analysis and visualization that would be impossible with raw text. Once entities, relationships, and events are extracted, they can be loaded into analytical tools, visualized as knowledge graphs, or integrated into business intelligence dashboards.
This allows for the identification of patterns, trends, and connections across multiple documents or within a single complex one. For example, by extracting regulatory requirements from various documents, an organization can instantly compare obligations, identify potential compliance gaps, or track changes over time. This high-level, organized view not only facilitates a deeper, more comprehensive understanding of the document’s content but also supports informed decision-making and operational efficiency.
Traditional AI Methods #
Traditionally, Information Extraction has been approached in two main ways.
- Rule-based systems, where you set up specific patterns to find the information. These are great for very consistent documents but can be a bit rigid if things change.
- Machine learning models learn from examples you provide. They’re more adaptable but require a significant upfront effort to “teach” them by labeling lots of data.
Each method has its sweet spot, depending on how predictable your documents are and how much data you have to work with.
Leveraging LLMs for Information and Relationship Extraction #
This is one of the most significant recent trends in information extraction, particularly for identifying relationships between entities. The field is moving away from fine-tuning specialized models toward leveraging the powerful text understanding and generation capabilities of large, general-purpose LLMs. Their innate ability to grasp context and nuance makes them a natural fit for the complex task of discerning relationships between entities.
Many LLMs (like GPT-3/4, Llama, Mistral, Claude, Gemma, etc.) can perform sophisticated relationship extraction with clever prompting. By designing prompts that explicitly ask the LLM to identify entities and the specific relationships that connect them, you can guide the model to output structured data without any additional training. Techniques like “Few-shot Learning” and “Chain-of-Thought (CoT) Prompting lead to results that are sufficient good for most use cases.